Sumo Logic ahead of the pack
Read articleOperational Visibility From AWS
Machine data holds hidden secrets that deliver true insights about the operational health of your AWS infrastructure. Learn more about operational visibility from AWS today!
Our approach resulted in a doubling of our log ingestion at an ingest cost increase of only 10%, saving us around $1 million.”
Iwan Eising
Team Lead of Service Reliability Architecture
BY OBSERVABILITY USE CASE
BY SECURITY USE CASE
BY INITIATIVE
BY COMPETITION
May 30, 2018
In a previous article of this series, we introduced Amazon S3 and Amazon Glacier, both suitable for storing unstructured or semi-structured data in the Amazon Web Services (AWS) cloud. In most cases, organizations have different types of databases powering their applications. AWS offers a number of robust, scalable and secured database services which makes them an ideal substitute for on-premise databases. In this article, we’ll compare some of the most popular AWS database services to help you select the right option for your organization.
Machine data holds hidden secrets that deliver true insights about the operational health of your AWS infrastructure. Learn more about operational visibility from AWS today!
AWS Relational Database Service (RDS) is Amazon’s cloud-hosted, managed RDBMS solution. With RDS, AWS customers don’t need to install, configure and manage popular relational database systems like Oracle, Microsoft SQL Server, PostgreSQL, MariaDB or MySQL. RDS allows users to spin up any of these database instances with minimal input from the user.
What this means is that users make a few fundamental choices, including the following:
Once the options are chosen, RDS provisions a database instance, changes any configuration settings and makes the instance available for the user.
Since this is a managed solution, users can’t directly access the underlying host for the simple fact that there is no remote desktop or SSH access at the operating system level. Behind the scenes, AWS takes care of all the installation, patching, maintenance, security, failover (for multi-AZ instances), snapshots, etc. Customers can either bring their own licenses for the database software, or purchase the license as part of the instance cost. With RDS automated backups, it’s also possible to restore an instance within five minutes of any point in time in the backup retention period. The retention can go back to the last 35 days.
Perhaps the best feature of RDS is its ability to scale. An RDS instance can be as small as having 1 vCPU and 2 GB RAM or as large as having 64 vCPUs and 488 GB RAM. If an instance needs more power, it can be upgraded to a higher-end server without any hassle at all. The underlying storage can be made to perform for a specified number of Input/Output (I/O) per second with provisioned IOPs. Achieving these types of scalability in a traditional data center would be time and cost intensive, if not prohibitive.
DynamoDB is Amazon’s footprint in the NoSQL world. NoSQL databases are very different from traditional RDBMS in that they have a flexible data model where a “row” of data may not have the same number of attributes as the next row. A NoSQL data model can store JSON documents or key value pairs and is typically hosted in a distributed computing environment for fault tolerance and redundancy.
Like RDS, Amazon DynamoDB is also a hosted and managed solution. That means users don’t have to maintain any servers, any networking or any fault tolerance to upkeep its distributed nature. All that the developers need to do is create tables in DynamoDB and start using them in the code.
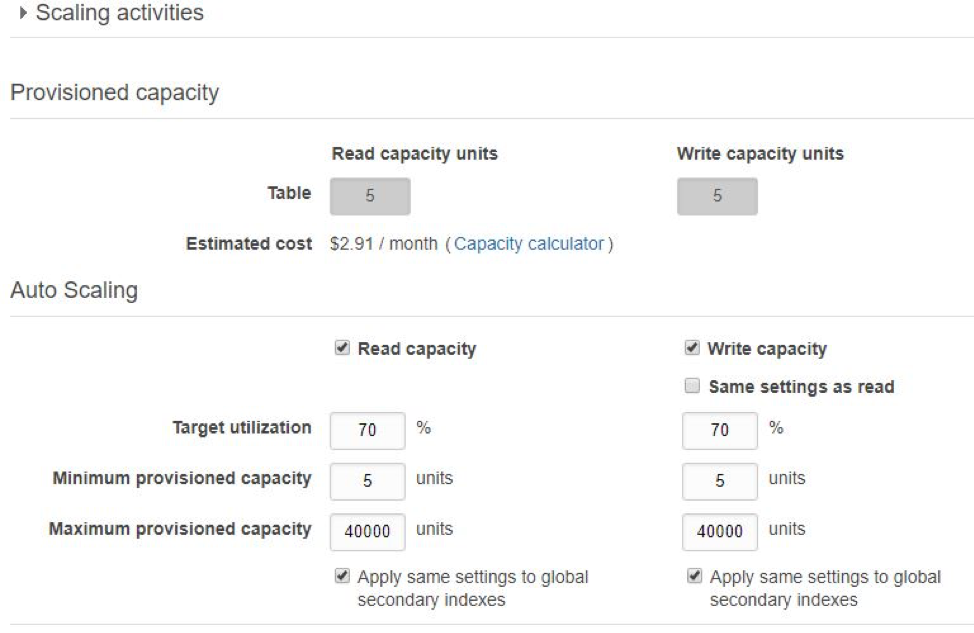
Like the disk storage attached to EC2 or RDS, DynamoDB also allows users to specify read and write throughput for its tables. This means throughput can be scaled on individual table basis. Whenever necessary to scale up or down to this throughput, DynamoDB would add or remove enough computing resources seamlessly, all behind the scene.
As a distributed system, DynamoDB also offers native replication between its different regions. Like RDS, it can also natively backup its tables when configured.
NoSQL databases are used as backends for modern cloud and web-based applications. They can be used to store user preferences or click-stream data, internet of things (IoT) streaming data and other types of non-structured or unstructured data from mobile apps and gaming software.
Many AWS customers run their database and storage workload in Amazon Elastic Compute Cloud (EC2) instances. EC2 is Amazon’s virtual server offering, much like VMWare virtual servers. Like S3, EC2 is one of the earliest and perhaps, the most widely-adopted service from Amazon.
AWS customers can run any type of operating systems in EC2 such as Linux, Windows or Solaris, and run database applications with the computing power. For example, it’s not uncommon to see two EC2 instances running Microsoft SQL servers in an AlwaysOn configuration. Similarly, a MySQL EC2 instance could be replicating data to another MySQL instance running a separate server.
Unlike RDS, DynamoDB, Redshift or EMR, running databases in EC2 gives flexibility to the customer. A company may decide to use Apache Cassandra or Aerospike as its NoSQL database, or it may want to run a Cloudera Hadoop cluster instead of EMR. It’s all possible with EC2. The installation, configuration and management may be a bit lengthy, but at the end of the day customers can create their database infrastructure exactly as they want.
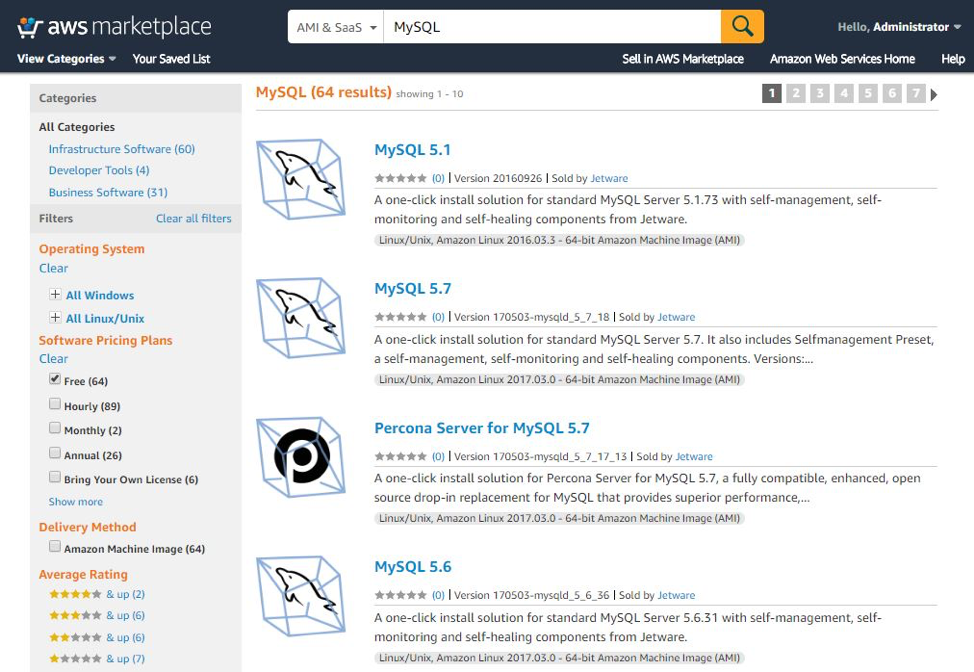
The installation part can also be skipped if custom Amazon Machine Images (AMIs) are used. AMIsare pre-baked, golden images of operating systems and applications installed in a server. AMIs are used as “templates” when creating an EC2 instance. There are many AMIs available with different databases software already installed and configured. Some are free, others have a payment model. These AMIs are available from the Amazon Marketplace. To get started quickly, customers can create their EC2 instances with one of these AMIs.
Databases require storage and EC2 can use three types of disk storage.
The first type is “instance store volumes,” which are storage drives that come with the EC2 instance itself. Typically they are not large enough to host large database files. These instance store volumes are also volatile in nature. That means any data that’s stored in these volumes are lost when the instance is shut down or rebooted. Obviously they are not suitable for persistent data, but they are good for temporary files, temp drives etc.
The second type of disk storage is the Elastic Block Storage (EBS) volumes. These are independent storage volumes that you can create and attach to an EC2 instance and then mount and format from the operating system. After that, the extra storage space becomes visible as a new volume or drive to applications running in the EC2 instance. As you need extra space, you can add more EBS volumes to the EC2 instance. If a volume is no longer needed, you can unmount it from the operating system and then detach it from the server. The volume is then marked as “available” so you can add it to another EC2.
EBS volumes can be created with different sizes and I/O throughput. It’s possible to create them as magnetic or SSD storage. It’s also possible to specify a “provisioned throughput”. With provisioned throughput, users can specify the I/O-per-second (IOPs) for the volume.
Another storage option for EC2 can be Amazon Elastic File System (EFS). Unlike EBS, EFS is not a block storage, it’s a network file system. This means users don’t need to create a disk volume with a specific size, and then attach and format that volume from the EC2 instance. With EFS, users create a fully-managed file system and then mount that file system to one or more EC2 instances.
As a managed storage, EFS can thus scale in size dynamically. As the demand for space grows, it can increase from gigabytes to petabytes in size without the user needing to do anything. All the user needs to do is ensure the file system is mounted on the required EC2 instances.
Another difference with EBS is backup. With EBS volumes, it’s up to the customer to create snapshots of the volume and maintain those snapshots. EFS file systems on the other hand are fully redundant, meaning Amazon takes care of the file system’s high availability.
Finally, EFS allows a file system to be shared among more than one EC2 instance — think tens, hundreds or even thousands of these, which is not possible with EBS. This can be an ideal solution for use cases like big data analytics, media servers, etc.
Some types of applications need blazing fast performance from their backend data tier. These are typically multi-user, distributed applications running in internet-enabled appliances like gaming consoles, mobile phones or smart devices. A disk-based database can’t simply cope with the scale and performance demands of these applications.
The answer lies in using in-memory data stores like Redis or Memcached, both of which can be used to store transient data in computer memory, thereby speeding up the performance manifolds.
ElastiCache is the managed in-memory database solution from Amazon. With ElastiCache, customers can deploy a fully-managed Memcached or Redis cluster very easily and start using those databases.
In memory databases like Amazon ElastiCache are typically required for high speed applications where sub-millisecond query performance is required.
Our third and final part in this series talks about AWS services for data warehouse and analytics workloads. You can read it here. Large organizations often deal with massive amounts of data and want to make business critical decisions from those mountains of data. This is where AWS can help with its cost-effective yet robust solutions. This article is helpful for those who need to know “what’s out there” and make an informed decision.
Reduce downtime and move from reactive to proactive monitoring.
Build, run, and secure modern applications and cloud infrastructures.
Start free trial
Sadequl Hussain is an information technologist, trainer, and guest blogger for Machine Data Almanac. He comes from a strong database background and has 20 years experience in development, infrastructure engineering, database management, training, and technical authoring. He loves working with cloud technologies and anything related to databases and big data. When he is not blogging or making training videos, he can be found spending time with his young family.
More posts by Sadequl Hussain.

No credit card required. Up and running in minutes.
More than 2,100 enterprises around the world rely on Sumo Logic to build, run, and secure their modern applications and cloud infrastructures.