
Full stack deployments are a relatively new concept to me. At first, I was confused as to why you would redeploy the entire stack every time, rather than just the code. It seems silly, right? My brain was stuck a little in the past, as if you were rebuilding a server from scratch on every deployment. Stupid. But what exactly is full stack deployment, and why is it better than “traditional” code-only deployment?
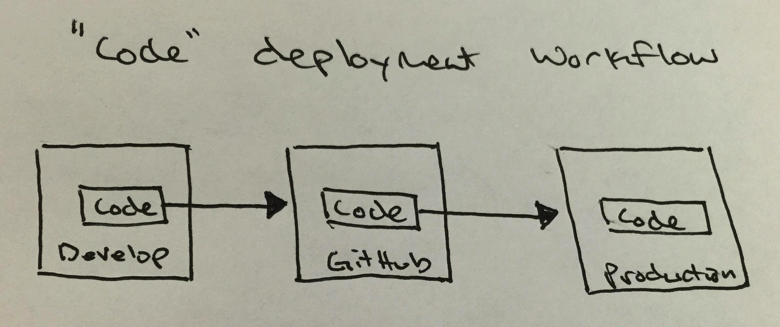
Traditionally, deployments involve moving code from a source code repository into a production environment. I know this is a simplistic explanation, but I don’t really want to get into unit testing, continuous integration, migrations, and all the other popular buzzwords that inhabit the release engineering ethos. Code moves from Point A to Point B, where it ends up in the hands of the end user. Not much else changes along that path. The machine, operating system, and configurations all stay the same (for the most part).
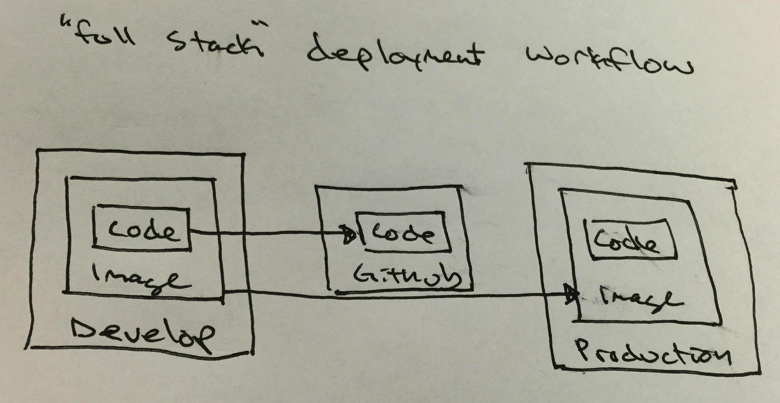
With full stack deployments, everything is re-deployed. The machine (or, more accurately, the virtual machine) is replaced with a fresh one, the operating system is reprovisioned, and any dependent services are recreated or reconfigured. These deployment are often handled in the form of a freshly configured server image that is uploaded and then spun up, rather than starting and provisioning a server remotely. While this might sound a little like overkill, it is actually an incredibly valuable way to keep your entire application healthy and clean. Imagine if you were serving someone a sandwich for lunch two days in a row. You would use a different plate to put today’s sandwich on than you used for yesterday’s sandwich wouldn’t you? Maintaining a consistent environment from development to production is also a great way to reduce the number of production bugs that can’t be reproduced on a development environment.
With the rise of scalable micro-hosting services Amazon EC2, this mindset has already taken hold a bit to facilitate increased server and network load. As the site requires more resources, identical server images are loaded onto EC2 instances to handle the additional load, and then are powered back down when they’re no longer needed. This practice is also incredibly valuable for preventing issues that can crop up with long-running applications, especially across deployments. Technologies like Docker do a good job of encouraging isolation of different pieces of an application by their function, allowing them to be deployed as needed as individual server images. As Docker and other similar services gain support, I think we will start to see a change in the way we view applications. Rather than being defined as just code, applications will be defined as a collection of isolated services.



{kind=link}
{kind=link}