
We are in the era of big data characterized by data sets that are too large, fast and complicated to be handled by standard methods or tools. An example of such kind of big data sets is machine-generated logs. At Sumo Logic, our analytics team has been focused on studying new techniques for summarizing, analyzing and mining machine-generated logs. Our production service is processing hundreds of terabytes of machine-generated logs per day. One technique contributing for such huge scalability is the min-hash, which is an instance of locality sensitive hashing.
Why min-hash?
Let us consider the problem of finding similar machine logs: provided n
where Jin[0,1]
then the min-hash function will map mboxlog
We can verify that the probability of two machine logs being mapped to the same bucket is equal to their Jaccard similarity, that is:
The min-hash technique has been widely used in industries such as news recommendation[4], near duplicate web page detection[1] and image search[5]. At Sumo Logic, our analytics team is adopting it for matching machine logs to signatures and also for inferring new signatures from machine logs.
Considering token weights
In min-hash, all tokens are considered to have equal weights, and therefore have equal probabilities to be selected as the token with the minimal hashing value. However in reality, we wish to treat tokens as having different weights, in particular in applications such as document retrieval, text mining and web search. A famous approach to weighting tokens in document retrieval is the inverse document frequency (idf)[2]. Let t
where nt
Like documents, machine logs consist of tokens, which we may wish to weigh differently. For example, in the machine log:
``INFO [hostId=monitor-1] [module=GLASS] [localUserName=glass] [logger=LeaderElection] [thread=Thread-2] Updating leader election; Found 18 elections to update",
bold tokens are more informative than others and thus we hope them have larger weights. It can also be useful to incorporate token weights when measuring the similarity between two logs, which in fact leads to the weighted Jaccard approach defined as:
The weighted Jaccard similarity is a natural generalization of Jaccard similarity. It will become Jaccard similarity if all token weights w(t)
Weighted min-hash
Suppose tokens have different weights and these weights are also known beforehand, the question now becomes how to incorporate token weights into min-hash so that similar logs under weighted Jaccard similarities have high probabilities to be mapped into the same bucket. Note in min-hash, the hashing function, which is a mapping from a token to a random integer, is only used for perturbing orders of tokens. That means you can use original tokens as hashing keys. You can also use randomly-generated strings as hashing keys. The advantage of randomly-generated keys is that you can assign different numbers of random keys to the same token according to its weight. In particular, tokens with large weights should be assigned more random keys, while tokens with small weights should be assigned less random keys. That is the core trick of weighted min-hash[3][6]. If all token weights are assumed to be positive integers which can be realized by scaling and discretization, then a simple approach is to generate w(t)
The weighted min-hash runs min-hash on randomly-generated keys, instead of original keys. The weighted min-hash function becomes:
where mboxrandom−keys(t)
Apart from the random keys method described above, monotonic transformation[3] is another approach for incorporating token weights into min-hash. In[3], the authors did a lot of experiments to compare min-hash and weighed min-hash for image retrieval and concluded that weighted min-hash performs much better than min-hash. Our analytics team got the same conclusion after running min-hash and weighted min-hash for machine log analysis.
[1] A. Rajaraman and J. Ullman, Mining of Massive Datasets, Cambridge University Press, 2012.
[2] K. Jones, A Statistical Interpretation of Term Specificity and Its Application in Retrieval, Journal of Documentation, pp. 11-21, 1972
[3] O. Chum, J. Philbin, and A. Zisserman, Near Duplicate Image Detection: Min-Hash and Tf-Idf Weighting, BMCV, pp. 493-502, 2008
[4] A. Das, M. Datar, and A. Garg, Google News Personalization: Scalable Online Collaborative Filtering, WWW, pp. 271-280, 2007
[5] O. Chum, M. Perdoch, and J. Matas, Geometric min-Hashing: Finding a (Thick) Needle in a Haystack, CVPR, pp. 17-24, 2009
[6] S. Ioffe, Improved Consistent Sampling, Weighted MinHash and L1 Sketching, ICDM, pp.246-255, 2010



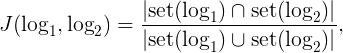{kind=link}
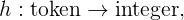{kind=link}
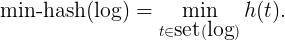{kind=link}
{kind=link}
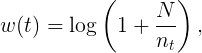{kind=link}
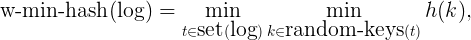{kind=link}
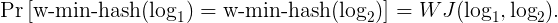{kind=link}