Resource Center

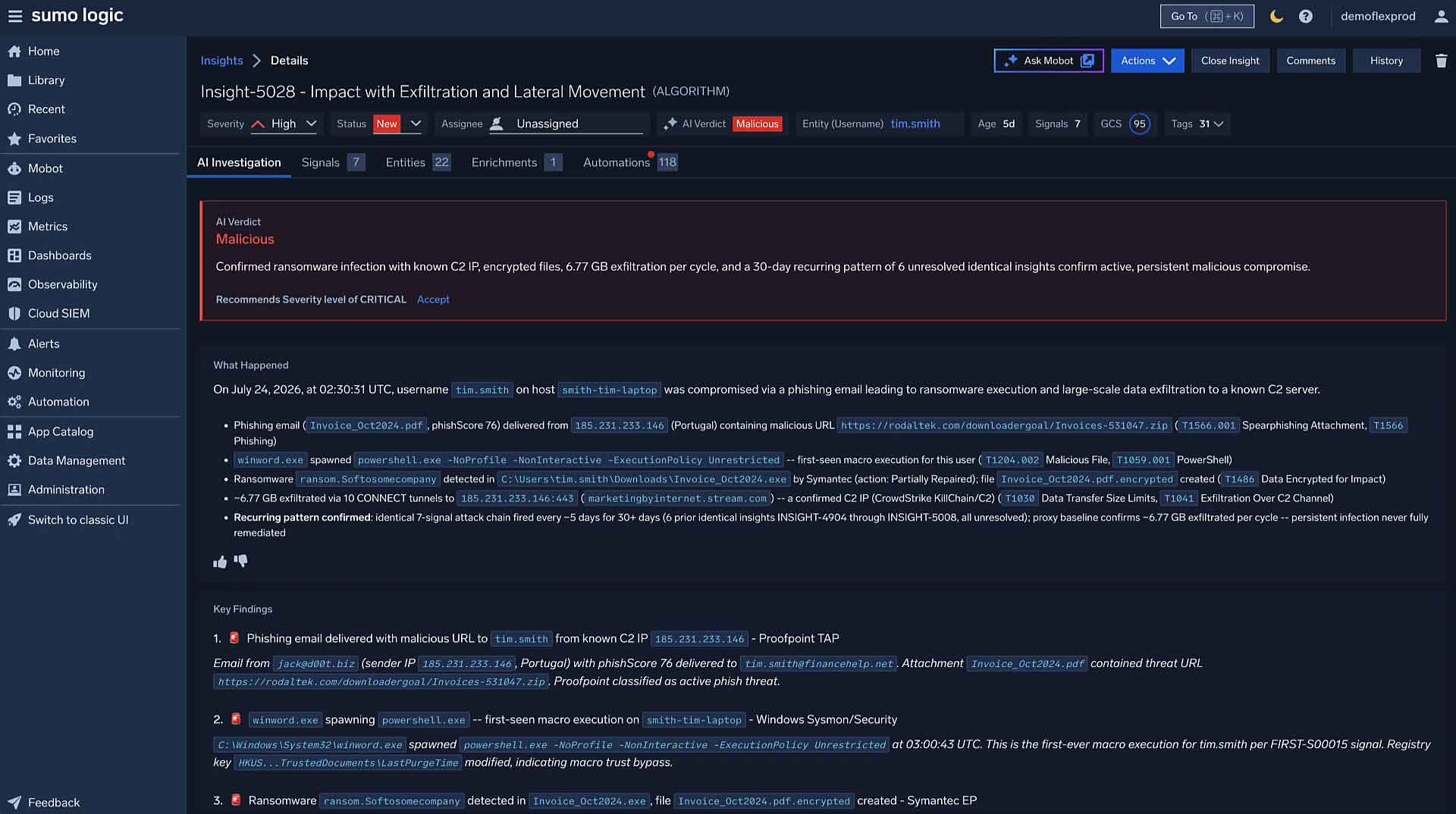
Mobot: Sumo Logic’s natural language AI for SOC investigations
Videos
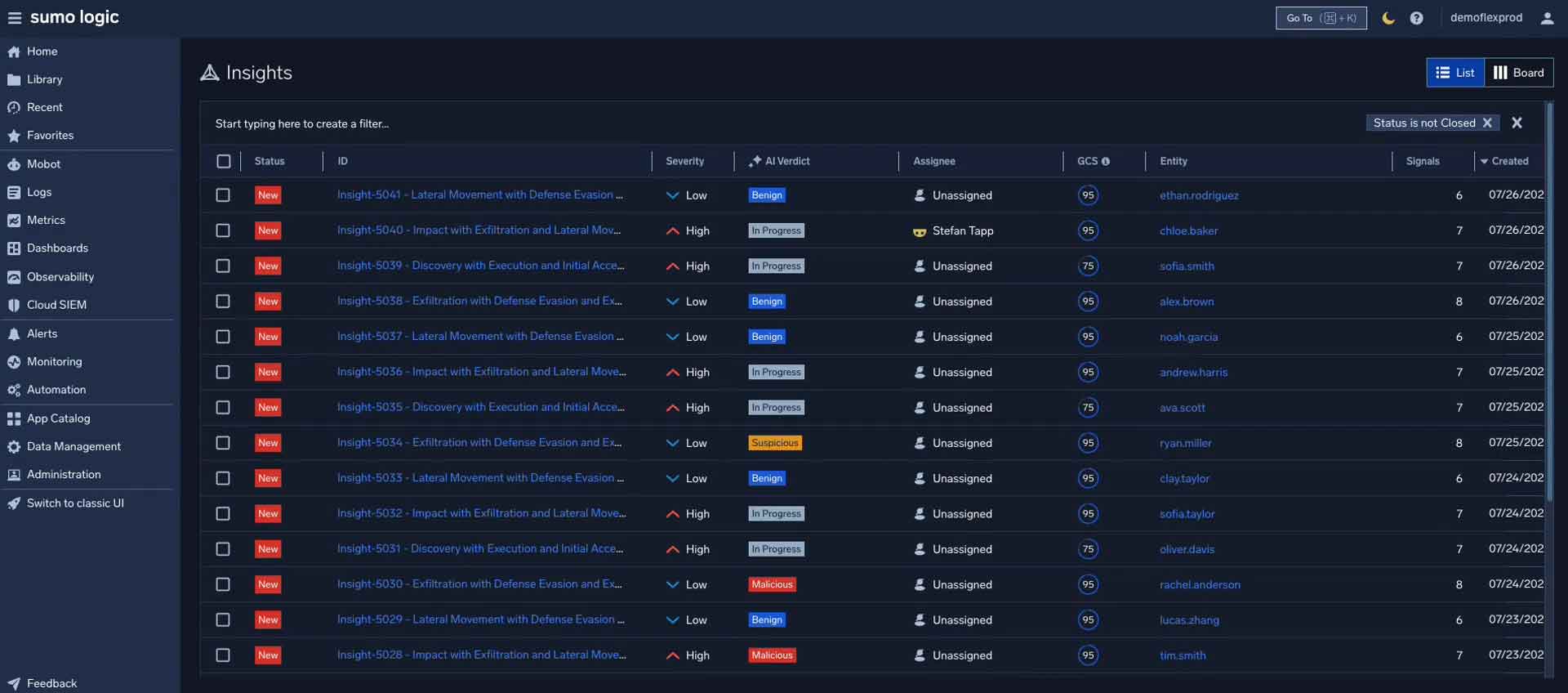
Sumo Logic’s SOC Analyst Agent: Automated triage for every tier one alert
Videos

Sumo Logic’s Dojo AI powers intelligent operations
Briefs

Black Hat FOMO? Dojo AI Demo
Podcast
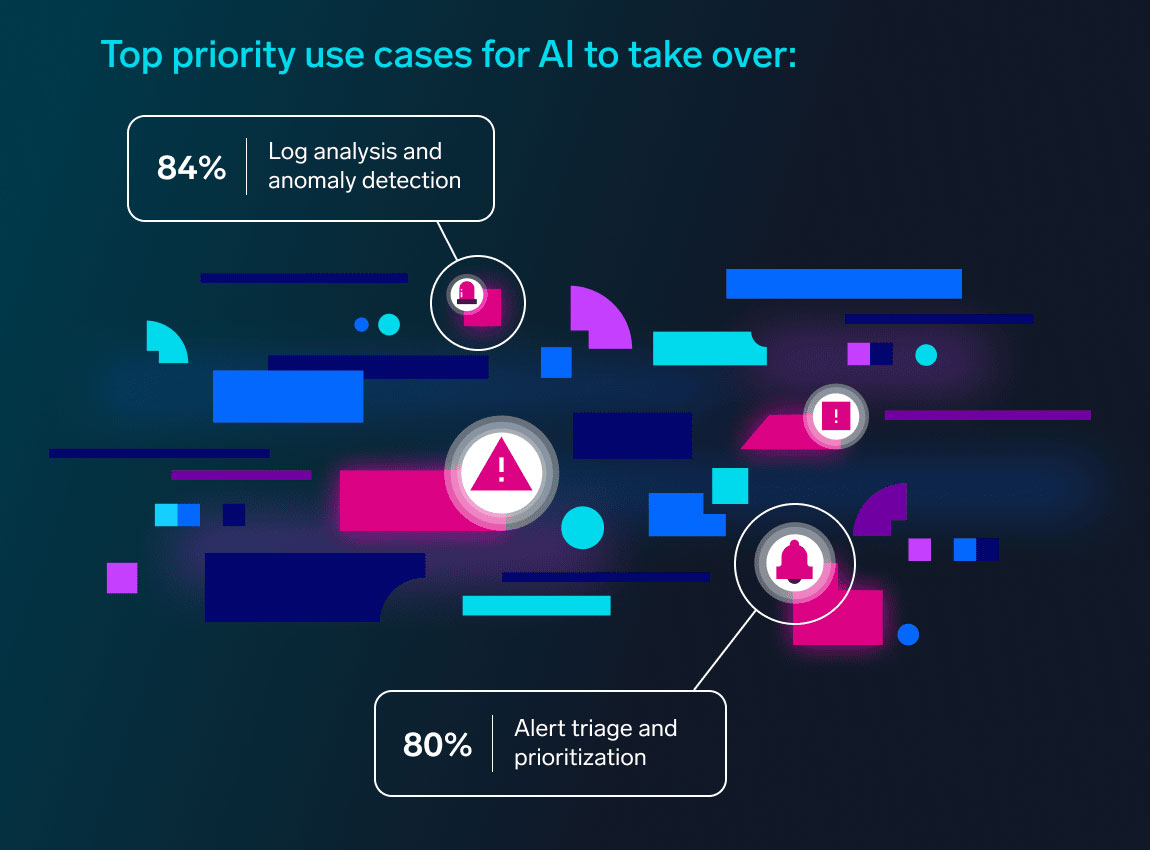
AI and cybersecurity: From prototype to production
Infographics

SIEM evaluation guide
Guides

I’ll have my AI agent call your AI agent: Battle for your digital hub
Podcast

Operating at galactic scale: Inside Sumo Logic’s agentic security program
Podcast

Called it (mostly): Checking in on 2026 predictions so far
Podcast